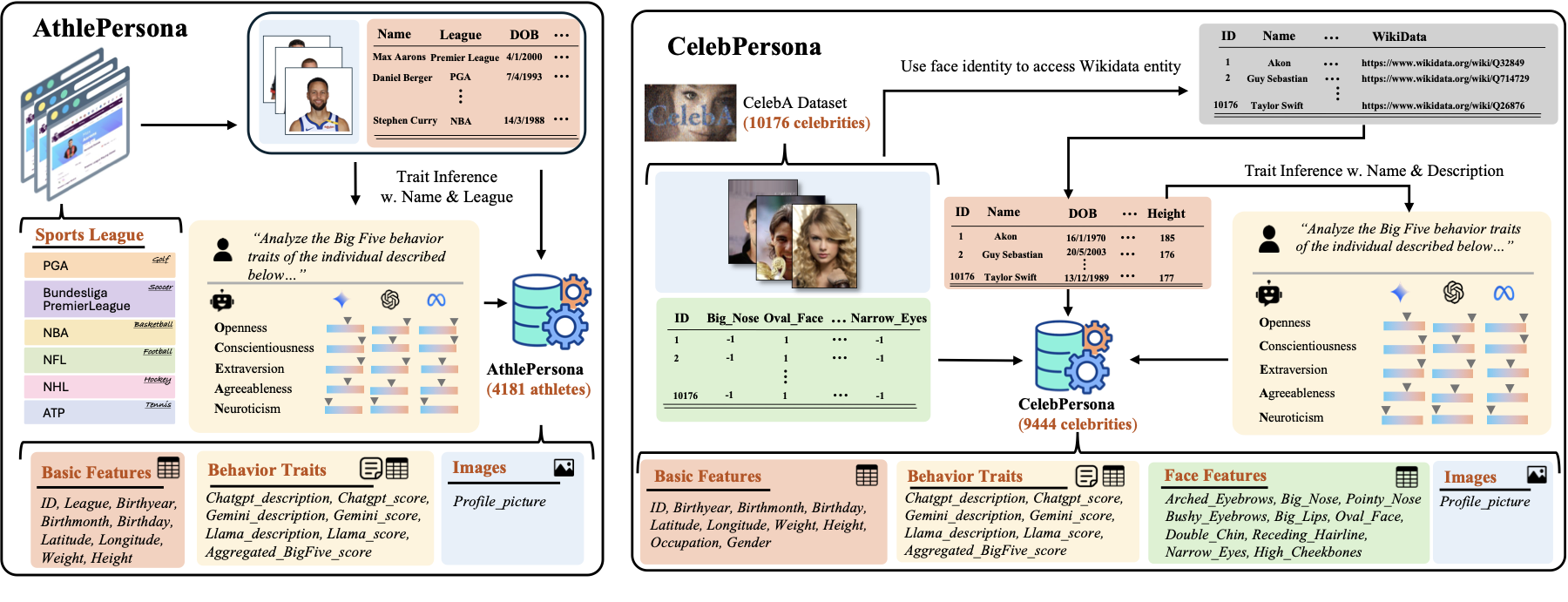
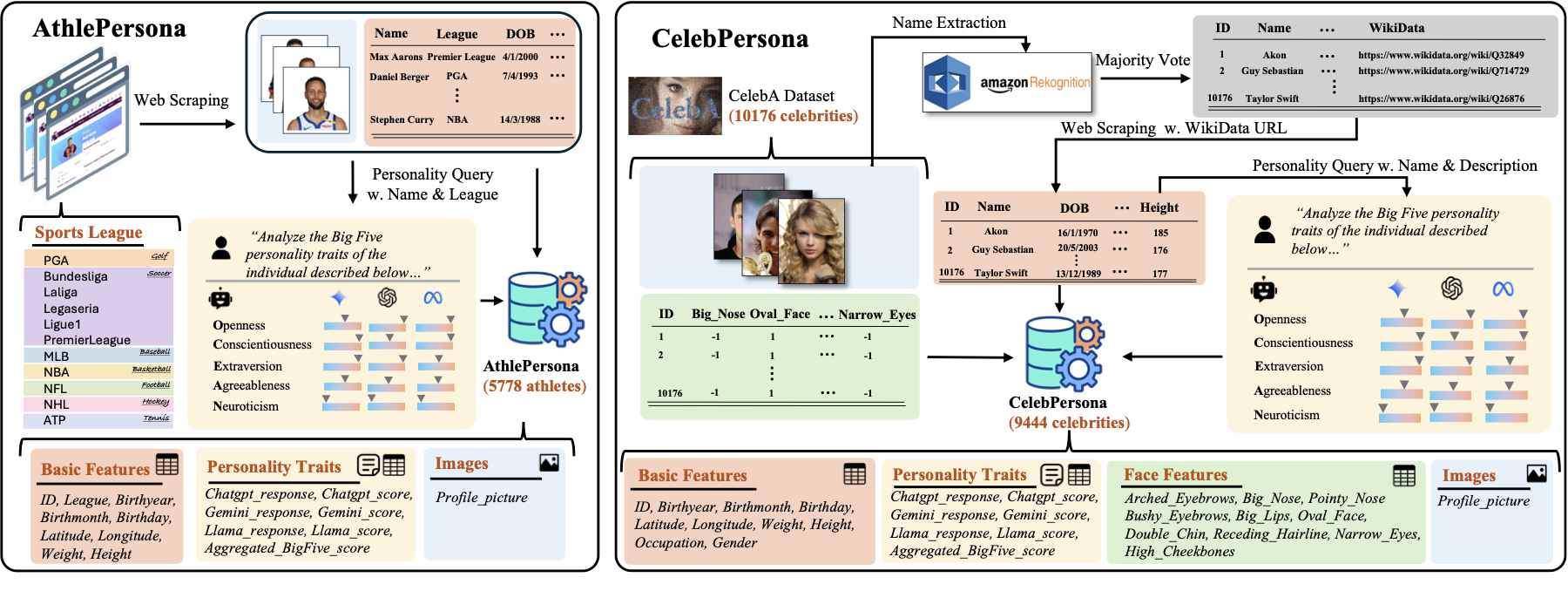
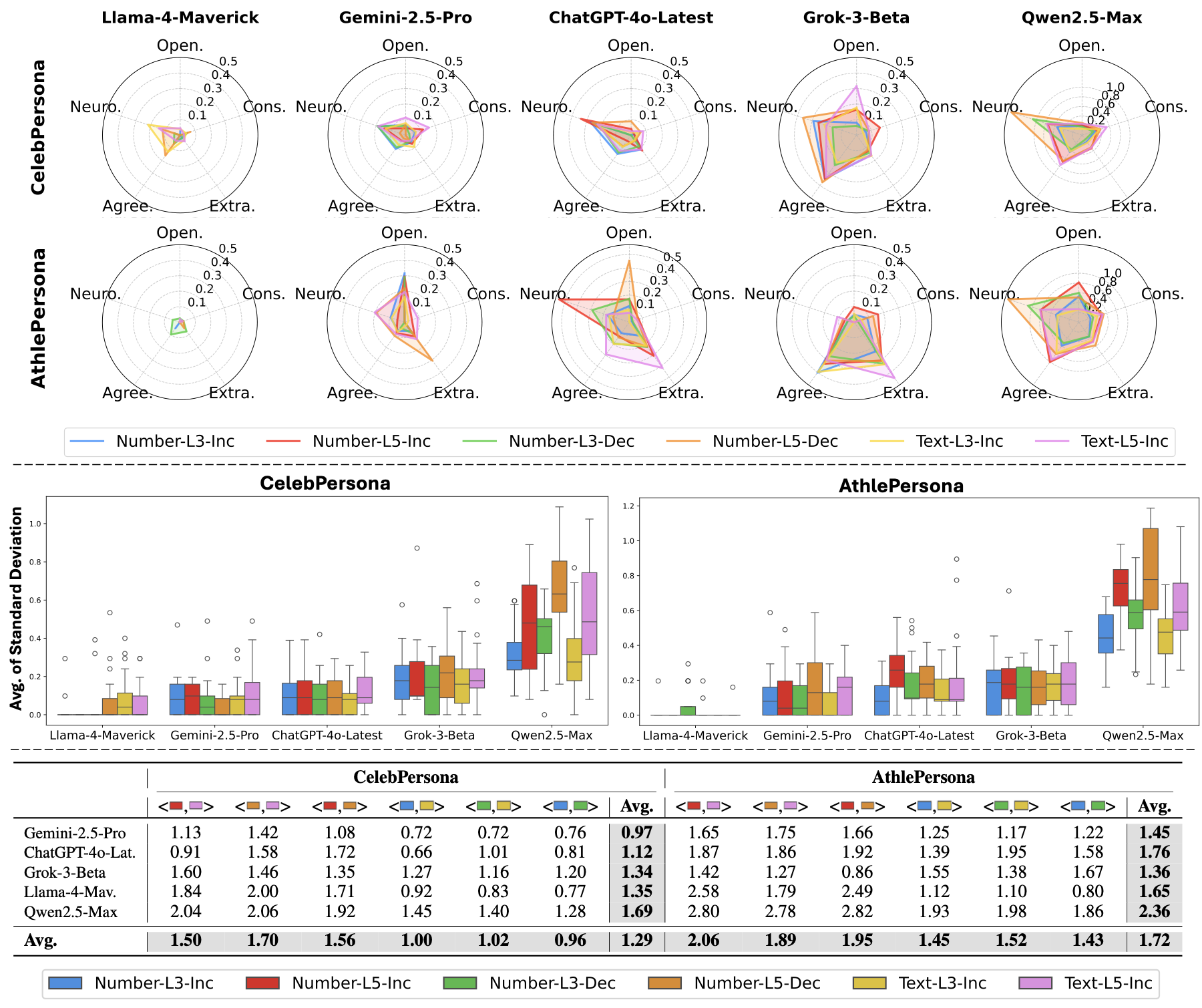
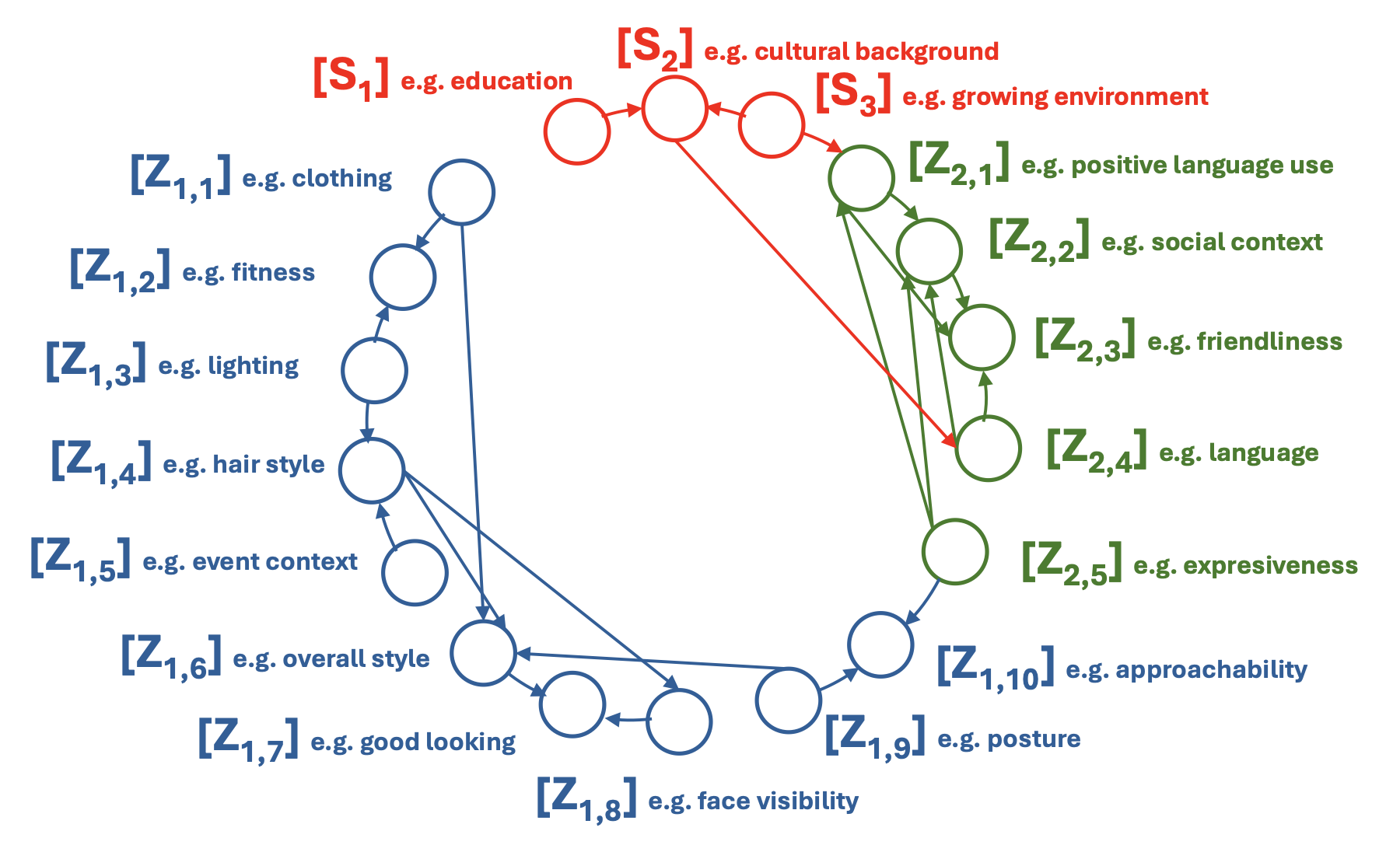
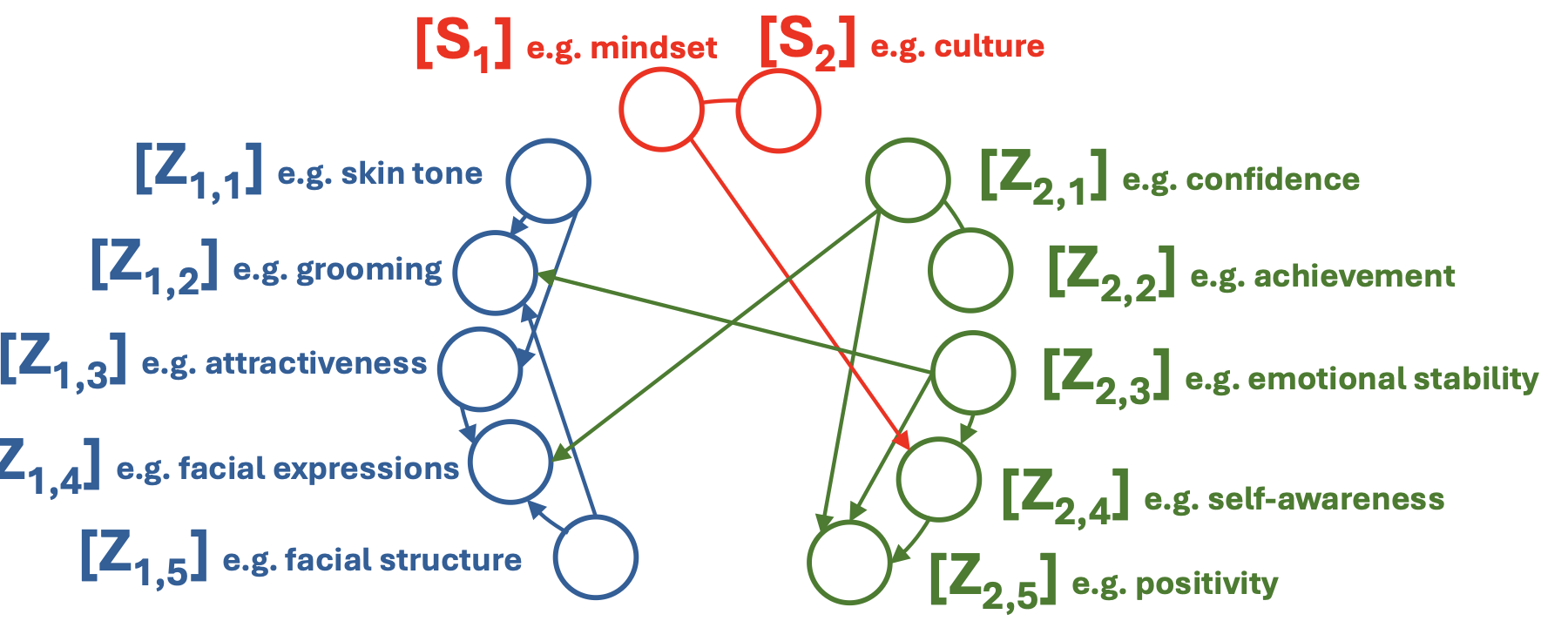
PersonaX is built to answer a simple question: can we study human behavior traits at scale without relying on self-reports or invasive measurements? We link LLM-inferred behavior traits to visual and biographical signals, enabling cross-modal analysis, causal discovery, and reproducible empirical study.
The result is a two-dataset suite that is large enough for population-level insights, but structured enough to support principled causal analysis.